 企业邮箱
企业邮箱







第二节 离散趋势指标
作者:徐荣祥 出版社:中国科学技术出版社 发行日期:2009年7月
离散(dispersion)趋势指标指的是计量资料所有观察值偏离中心位置的程度(measures of variation)。描述离散趋势的主要统计指标有全距(range,R)、方差(variance)、标准差(standard deviation)、变异系数(coefficient of variation)等。
一、全距
全距又称极差,以符号R表示。R等于一个变量的所有观察值中最大值(maximum,Max)与最小值(miximum,Max)之间的差值。计算公式为(368):R=Max-Max。当计算计量单位相同的变量时,全距越大,观察值的离散程度越大。
如一组烧伤病人的最大烧伤面积为90%TBSA,最小面积为10%TBSA,按公式(368)计算,R=90-10=80%TBSA。
二、方差
方差是离均差平方和的平均值,方差的大小只与观察值离散程度有关,而与观察值个数的多少无关。样本方差以符号S2表示,是总体方差的估计值,按公式(369)计算:
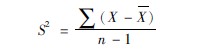
式中∑(X-X)2为离均差平方和, n-1为自由度(n′)。因总体方差不易得到,实际工作中常用样本方差作为总体方差的估计。
方差多用于方差分析或两个样本标准差合并计算之用。如甲组25人,标准差为28,乙组46人,标准差为22,两组合并标准差公式为(369):
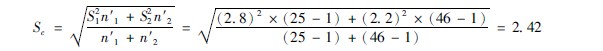
三、 标准差
根据上述见解,全距系指一组变量值中最大值与最小值的差;标准差则表示这一组变量值分布的离散程度。为进一步说明其离散程度,试看下面这两组数据:
A组:80、90、100、110、120(平均数=100)
B组:98、99、100、101、102(平均数=100)
这两组数值的均数都是100,但是变量值的波动范围却有很大差别,A组数据最大值与最小值之差(全距)为40(120~80),B组数据最大值与最小值之差(全距)为4(102~98)。由此可见,A组数据的波动范围比B组大得多。故均数不能完全说明事物内部的实质,需要用标准差来综合分析。目前认为反映数据精确度较为完善的指标就是标准差。
又如:甲组5例病人的烧伤总面积分别为90%、80%、70%、21%、9%TBSA,平均为54%TBSA;乙组5例病人的烧伤总面积分别为100%、49%、49%、36%、36%TBSA,平均值也为54%TBSA,但甲组特重度病人有3例,乙组仅有1例。两组均值虽然相等,但并无同质性和可比性,同时也可看出标准差的重要性。因为标准差是一个个体数据偶然性波动大小的标准尺度,标准差大,表示个体数据波动性大,标准差小,表示个体数据波动性小。
四、标准差计算
1直接计算公式(3610):
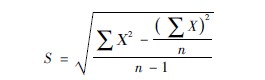
S为标准差,∑Χ2为变量值平方后的和,(∑x)2是变量值总和后的平方,n为变量个数。
示例365:测得9例创面出血病人的血小板数量分别为:30、50、40、40、50、40、30、50、149(×109/L),求它们的标准差。
【解题步骤】
先分别求出公式(3610)中的∑Χ2和(∑Χ)2/n,及n-1值,然后代入公式。
因为∑Χ2为变量值平方后的和,即:
∑Χ2=302+502+402+402+502+402+302+502+1492=36301
[(∑Χ)2]/n=(30+50+40+40+50+40+30+50+149)2/9=254934
(n-1)为(9-1)=8
代入公式(3610),得:
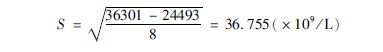
答:9例创面出血病人的血小板标准差为36755×109/L。
2大样本加权法公式
计算大样本资料,应绘制频数表资料,根据公式(3611)计算标准差:
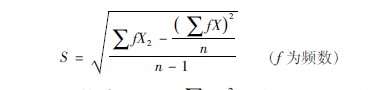
式中∑fX为各组段X与本组段频数乘积之和,∑fΧ2为各组段fx与本组段X乘积之和。
示例366仍以例362为例,即某院调查了110例特重度烧伤病人的血液血红蛋白含量,其浓度范围在115~150 g/L之间,求其标准差。
【解题步骤】
根据表362中提供的数据,将(∑f)=110、(∑fX)=13194、(∑fΧ2)=1584990代入公式(3611),得:
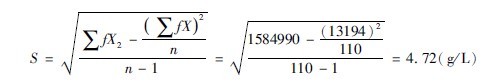
结果:110例烧伤病人的血红蛋白标准差为472g/L。
五、变异系数
在统计学上将变量值间的差异称为变异,表明这种变异的指标有全距、标准差和变异系数。如上所述,标准差的作用是用来确定两组数据的波动程度,一般情况下,哪一个标准差大,哪一组的数据波动范围也大;哪一个标准差小,其波动范围也小。但是,当比较不同类型的数据时,如身长与体重,或两个平均数相差较大时,若直接用标准差判断它们的波动程度就不妥当了,因为标准差只能反映绝对波动大小,不能反映相对波动大小。这种表达相对数波动大小的指数称为变异系数,用cv或ν表示。该指标也可理解为用百分比表示的标准差,即标准差(s)与均数(X)之比。其公式为(3612):

示例367某院调查了7岁男孩身高均数为12116cm,标准差为431cm,胸围均数5771cm,标准差为282cm。比较两者的变异程度。
【解题步骤】
根据公式(3612),分别求身长变异系数和胸围变异系数:
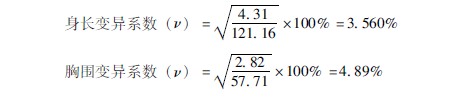
答:本例身长均数明显大于胸围均数,若与标准差直接比较,胸围的变异系数似乎小于身长,但经过变异系数计算,结论为胸围的变异程度并不比身长变异程度小。由此可见,身长的变异程度比胸围稳定。
六、标准误
因为均数的标准误与样本标准差相似,都是说明离散程度的指标,故在此作一介绍。变异系数均数标准误有两种,一种是总体标准误,一种是样本标准误。总体标准误(σx)和样本标准误(sx、SE、SEM)是表示均数误差程度的指标。在医学研究中,常在总体中抽出一部分作为样本,然后再根据样本的观察结果推论总体情况。但是,由于在同一总体中的个体之间必然存在着差异(如同是50%TBSA烧伤),样本均数与总体均数之间存在差异,各个样本均数之间必然产生差异,谓之标准误(sx),是由抽样引起的。标准误越小,说明样本均数与总体均数越接近,用样本均数推论总体均数的可能性越大;反之,标准误越大,说明用样本均数推论总体均数的可能性越小。故均数标准误是测定样本均数变异范围的尺度。在医学资料中,常用样本均数±标准误的形式(x±sx)表示资料的可靠程度。一般来说,在x±1×sx的范围内,总体均数出现的概率为683%;在x±2×sx的范围内,总体均数出现的概率为95%,或者说有95%以上的把握可认为总体均数在这个范围之内,也可认为重复同样实验100次,得出100个均数,会有95%以上的均数分布在x±2×sx的范围内。公式(3613)为: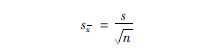
sx为标准误,s为样本标准差,n为样本个数。
示例368某院抽查了100例病人的血液红细胞数量,其样本均值为50×109/L,样本标准差为246×109/L,求其标准误。
【解题步骤】
根据公式(3613),求得:
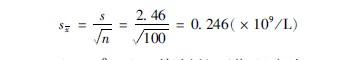
答:本例样本标准误为0246(×109/L),资料的可靠程度为50±0246(×109/L)。
七、平均数、标准差、标准误的应用
1表示正常范围如体温、脉搏,血压,红细胞,白细胞等正常值等计算均需要标准差的参与。正常值范围一般是以平均数±2个标准差作为划定界限,现以红细胞为例说明这个问题。如我们所求得的健康男子红细胞平均值为50×109/L,标准差为25×109/L,则正常男子红细胞的正常值可定为50±2×25,即45×109/L~55×109/L范围内。但应注意,在应用此方法时,变量的分布必须是正态分布,如属于非正态分布者,应采取其他方法计算。
2估计受试对象所需样本数
(1)利用标准误公式推算样本数:
示例369某医院测定了80名严重烧伤患者早期血液肌酐(Cr)含量,测定结果:均数(x)=1548μmmol/L,标准差(s)=158μmmol/L ,标准误=1778μmmol/L, 即目前95%的置信限为1548±354μmmol/L ,欲求95%的置信限在158±20μmmol/L的范围内,需要观察多少例才能出现这种结果?
【解题步骤】
①根据标准误计算公式(3613)推算样本数(n),公式为(3614):
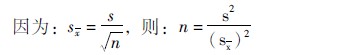
②因为95%的置信限为x±2×sx,今求2×sx=20,即sx=10。把有关数据代入公式(3614),得:
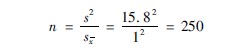
③结论:若把观察人数增加到250人,可能使置信限范围达到1548±20μmol/L 。
(2)利用两合并标准差推算样本数:
示例3510某医生用某药治疗粒细胞减少症,为观察某药物用口服方法及肌肉注射方法对最高疗效出现时间(天)的影响。根据预备试验结果,口服法最高疗效出现的平均时间为222天,肌肉注射法为175天,合并标准差(s)为1391天。问各组需观察多少例才能使两组均数的差异有显著意义?
【解题步骤】
①本例是两个样本平均数作比较的资料,当两组样本相等时,其样本大小的估计公式为(3615):
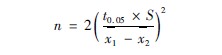
n=每组例数,t005=表中查出的标准值,s=合并标准差,x1-x2=两组均数差。
②当n≥30时,查表得出t005=20,因x1-x2=475,s=1391,代入公式(3615):

③结论:每组需要观察69例才能使两组均数差异有显著意义。